AutoGL and the Open Graph Benchmark: Datasets for Machine Learning on Graphs
AutoGL and the Open Graph Benchmark: Datasets for Machine Learning on Graphs
Just a quick presentation and notes about relatively new tools and datasets for machine learning on graphs.

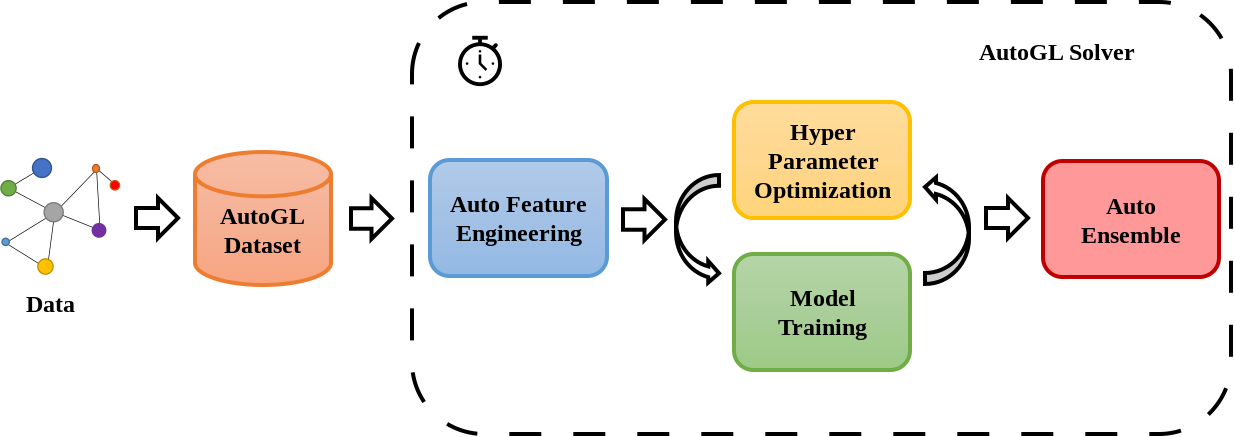
Getting started with AutoGL
A simple ‘Getting Started’ example: The Cora dataset is the MNIST equivalent in graph learning.
Dataset description:
- The Cora dataset consists of 2708 scientific publications classified into one of seven classes.
- The citation network consists of 5429 links.
- Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1433 unique words.
Task:
- Predict the class of the publication from (‘Case_Based’, ‘Genetic_Algorithms’, ‘Neural_Networks’, ‘Probabilistic_Methods’, ‘Reinforcement_Learning’, ‘Rule_Learning’, ‘Theory’).
import torch
from autogl.datasets import build_dataset_from_name
from autogl.solver import AutoNodeClassifier
from autogl.module.train import Acc
cora_dataset = build_dataset_from_name('cora')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
solver = AutoNodeClassifier(
feature_module='deepgl',
graph_models=['gcn', 'gat'],
hpo_module='anneal',
ensemble_module='voting',
device=device
)
solver.fit(cora_dataset, time_limit=3600)
predicted = solver.predict_proba()
print('Test accuracy: ', Acc.evaluate(predicted,
cora_dataset.data.y[cora_dataset.data.test_mask].cpu().numpy()))
Test accuracy: 0.824
If you want to run the code, you can have a look at this colab notebook.
Open Graph Benchmark: Datasets for Machine Learning on Graphs
Issues with current benchmarks
According to the paper:
-
They are too small, i.e. a few thousand nodes, compared to graphs found in real applications.
-
There is no unified and commonly-followed experimental protocol. Different studies adopt their own dataset splits, evaluation metrics, and cross-validation protocols, making it challenging to compare performance reported across various studies.
-
Many studies follow the convention of using random splits to generate training/test sets, which is not realistic or useful for real-world applications and generally leads to overly optimistic performance results.
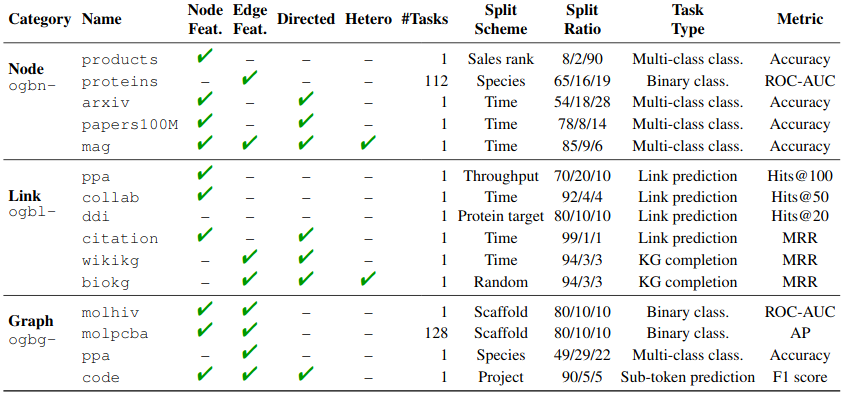
Thus, there is an urgent need for a comprehensive suite of real-world benchmarks that combine a diverse set of datasets of various sizes coming from different domains. Data splits as well as evaluation metrics are important so that progress can be measured in a consistent and reproducible way. Last but not least, benchmarks also need to provide different types of tasks, such as node classification, link prediction, and graph classification.
Furthermore, for each dataset, OGB adopts domain-specific data splits (e.g., based on time, species, molecular structure, GitHub project, etc.) that are more realistic and meaningful than conventional random splits.
Datasets available in OGB:
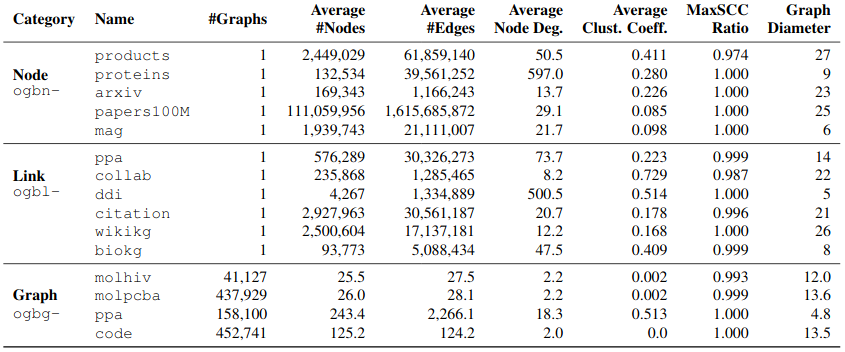
Summary statistics of the graphs in the datasets:
Applications in Finance
There are many potential applications within finance.
However, (networks) datasets are usually quite expensive (to build and maintain yourself from public information, or to buy from a data vendor; in the latter case, they come with tight license and sharing restrictions) with 6+ digits USD price tags.
Sometimes, these datasets are proprietary and cannot be used outside the firm which owns the datasets due to confidential information and/or competitive edge as illustrated by this excellent study on 2.4M Italian firms interconnected through corporate payments (Corporate payments networks and credit risk rating by Letizia and Lillo) showing the existence of an homophily of risk, i.e. the tendency of firms with similar risk profile to be statistically more connected among themselves.
This paper “Corporate payments networks and credit risk rating” approaches the problem with standard ML models (multinomial logistic, classification tree, vanilla neural network) and typical network features to describe a firm, i.e. a node in the network (in-degree, out-degree, hierarchy position, size, percentage of neighbours with such or such credit ratings). It would be interesting to revisit this study (prediction of ‘missing’ credit ratings) using Graph Neural Networks to see if they are able to beat their baseline.
Unfortunately, this is not possible since the data is not available. This is why I have been advocating for more reproducibility in financial networks research, and I think generative models such as GANs could help sharing anonymized non-sensitive versions of the datasets with similar statistical properties (useful for research to gain more knowledge) but not hurting the competitive edge (impossibility for competitors to act on the information) directly.
Besides the prediction of missing credit ratings using the corporate payments networks, one can also revisit the typical Supply Chain datasets and strategies (cf. this white paper from Bloomberg: Supply chain momentum strategies with graph neural networks).