[ICML 2019] Day 1 - Tutorials
[ICML 2019] Day 1 - Tutorials
Day 0 of ICML this year was dedicated to presentations from industry sponsors.
The first day of the ICML 2019 conference consisted in four tutorial sessions of three tutorials in parallel each (cf. the full schedule here).
From these tutorials, I attended the following:
- Safe Machine Learning:
- Not many takeaways for me on this one, but that Reinforcement Learning is tricky, buggy, and that researchers at DeepMind are working hard to avoid the so called ‘surprising creativity of digital solution’ which are faulty behaviours that exploit a faulty misspecified reward function. These things are easy to spot on (computer) games, but for more abstract applications, good luck! The discussion went on different ways to prevent such behaviors: putting a human in the loop, restraining the action space (blocking some obviously bad actions), some potential theoretical verification of neural networks against adversarial attacks (you add some invisible noise to an image, or change a single pixel, and the classifier is totally fooled) by checking properties of stability around the boundaries (but doesn’t scale well as requiring the solution of some NP-complete problem, SAT). Nonetheless, for a precise (specific) definition of robustness, some small 6-layer perceptron (~13,000 parameters) was verified robust to adversarial attacks. Also, biases of data/models were mentioned: the COMPAS software which is a decision support tool to identify the likelihood of a defendant becoming a recidivist has been shown to be biased against black people. Hence, the trendy research question of how to properly define ‘fairness’. In the academic literature, dozens of different definitions co-exist which are not consistent between themselves. Ongoing research… In conclusion, this tutorial provided (at least to me) quite a gloomy picture of machine learning capabilities (in the wild) with respect to taking important decisions for people’s lives (from loan to education and justice).


- Active Learning: From Theory to Practice
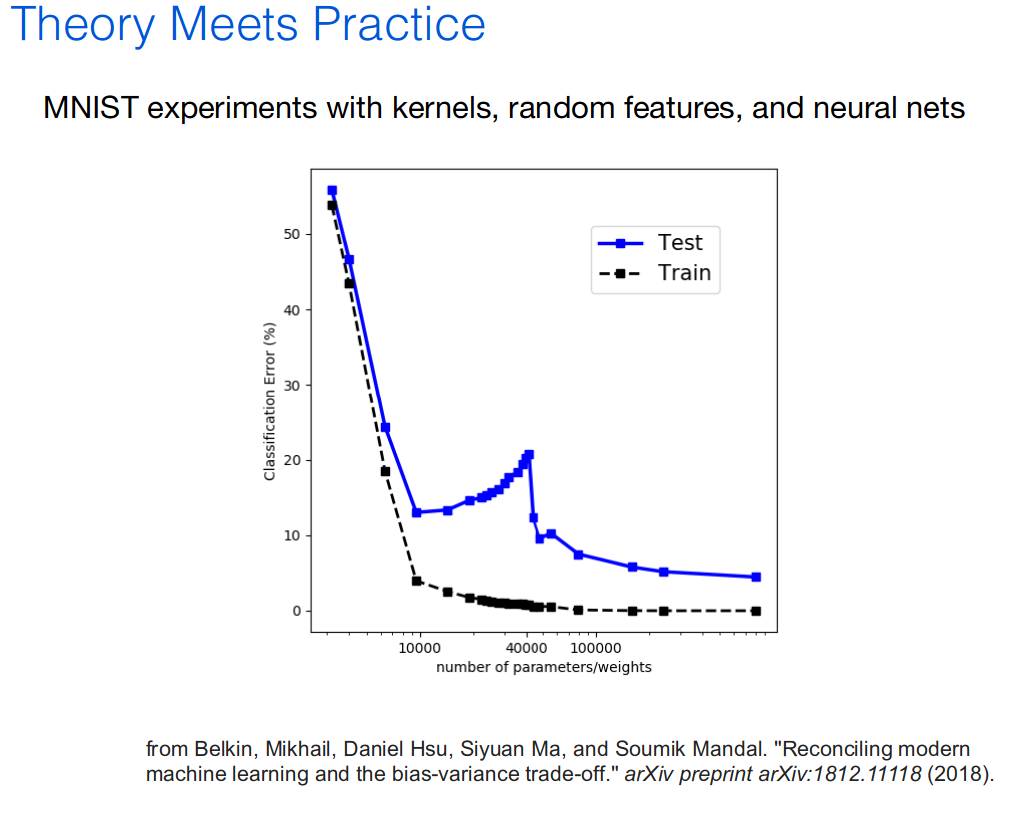
- I attended this tutorial as I find that Active Learning is highly relevant for a practitioner. Active Learning aims to train machines with less labeled data and less human supervision. What not to like? If you are someone who spent countless hours labeling with various tricks some niche data, you will understand. Active Learning gathers a set of techniques and theories on how machine can automatically and adaptively selects the most informative data for labeling. Thus, the human can only focus on the data points that ‘matter’ for improving the machine learning model. Baseline for this field is the ‘no labeling strategy’, that is sample at random (uniformly) points to label. An active strategy would be to present the labeler with points that are near the best decision boundary given the points labeled so far. Prof. Nowak mentioned Hierarchical Clustering as a way to do some active learning, idea coming from an ‘old’ paper I wasn’t aware of. I used similar techniques (hierarchical clustering and flat clustering for labeling), which are quite natural ideas, in the past but without much theoretical understanding. I’ll look into the details. More thought provoking were the slides 9-12 of part 4 of the tutorial. Basically, in the classic standard textbooks on statistical learning you are told quickly about the bias-variance trade-off, and you can see the following picture everywhere:

But actually, what can happen is more like that:

For example (cf. this paper), on a ‘real’ dataset (MNIST…):
- A Tutorial on Attention in Deep Learning:
- I learned about the existence of this interactive book: Dive into Deep Learning. Otherwise, it was a pedagogical explanation and review of the short and recent history of the attention concept. I will try to get the slides.
Edit (30 June 2019): I finally found the slides, there.